AI tự động phát hiện ngôn ngữ trong cuộc hội thoại
Phản ánh ngữ điệu và phong cách nói... thời gian trễ chỉ vài giây
Áp dụng từ ứng dụng dịch thuật... Google Meet thử nghiệm cho khách hàng doanh nghiệp
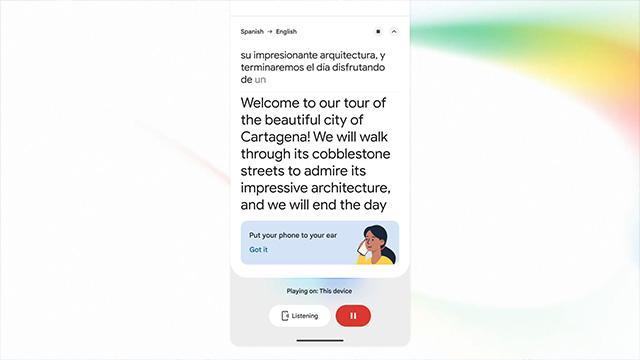
Vào ngày 9 tháng 6, Google đã giới thiệu mô hình dịch giọng nói thời gian thực mới mang tên 'Gemini 3.5 Live Translate'. Mô hình này sẽ được áp dụng lần lượt cho ứng dụng Google Dịch, dịch vụ hội nghị video Google Meet, và API Gemini Live dành cho các nhà phát triển (công cụ tích hợp chức năng giọng nói thời gian thực).
Mô hình mới có khả năng tự động nhận diện ngôn ngữ trong cuộc hội thoại mà không cần người dùng phải chọn ngôn ngữ dịch trước. Nó có thể nhận diện giọng nói bằng hơn 70 ngôn ngữ và chuyển đổi sang giọng nói của ngôn ngữ khác. Mô hình này cũng có thể sử dụng trong các cuộc hội thoại có nhiều ngôn ngữ khác nhau.
Sự thay đổi lớn nhất là tốc độ dịch. Trong khi các dịch vụ dịch giọng nói trước đây thường phát âm giọng nói dịch sau khi người nói kết thúc, mô hình mới cho phép phát âm giọng nói dịch trong khi người nói đang nói. Google cho biết sự khác biệt giữa giọng nói gốc và giọng nói dịch chỉ ở mức vài giây.
Chất lượng giọng nói cũng đã được cải thiện. Mô hình không chỉ dịch nghĩa của câu mà còn cố gắng phản ánh ngữ điệu, phong cách nói, tốc độ nói và cao độ của người nói gốc. Mục tiêu là tạo ra giọng nói dịch gần gũi với cuộc hội thoại thực tế, không phải chỉ là giọng nói đọc máy móc.
Mô hình mới sẽ được áp dụng cho cả ứng dụng Google Dịch trên Android và iOS. Người dùng có thể kết nối tai nghe để nghe dịch giọng nói thời gian thực. Trên Android, có chế độ 'Nghe' cho phép người dùng nghe giọng nói dịch giống như khi gọi điện thoại bằng cách đặt điện thoại lên tai.
Với tính năng này, người dùng có thể nhận được dịch giọng nói gần như thời gian thực khi trò chuyện với người dân địa phương trong chuyến du lịch, mặc dù họ nói các ngôn ngữ khác nhau.
Đối với Google Meet, tính năng này sẽ được áp dụng trước tiên cho một số khách hàng doanh nghiệp. Google dự kiến sẽ thử nghiệm tính năng dịch giọng nói mới này cho khách hàng Google Workspace trong tháng này và mở rộng đối tượng áp dụng trong năm nay. Tính năng này sẽ được sử dụng để dịch và truyền đạt phát biểu trong các cuộc họp đa ngôn ngữ.
Đối với các nhà phát triển, tính năng sẽ được công bố thử nghiệm thông qua API Gemini Live và Google AI Studio. Các nhà phát triển có thể sử dụng tính năng này để tạo ra dịch vụ dịch giọng nói thời gian thực. Các nền tảng truyền thông thời gian thực như Agora và LiveKit cũng hỗ trợ tích hợp các chức năng liên quan.
Dịch vụ gọi xe Grab đang thử nghiệm cách sử dụng mô hình này cho các cuộc gọi đa ngôn ngữ giữa tài xế và hành khách. Khi tài xế và hành khách nói các ngôn ngữ khác nhau, ứng dụng sẽ cung cấp dịch giọng nói thời gian thực.
Google cho biết sẽ áp dụng công nghệ watermark Synthesis ID cho tất cả các giọng nói được tạo ra bởi AI, để có thể nhận diện được giọng nói do AI tạo ra. Watermark Synthesis ID là công nghệ chèn dấu hiệu nhận diện vô hình vào giọng nói được tạo ra bởi AI.
* Bài viết này được dịch tự động bằng AI.

© Bản quyền thuộc về Thời báo Kinh tế AJU & www.ajunews.com: Việc sử dụng các nội dung đăng tải trên vietnam. kyungjeilbo.com phải có sự đồng ý bằng văn bản của Aju News Corporation.